|
João Valente, Arminda Guerra [Winner] |
||
|
Escola Superior de Tecnologia |
||
|
Tao Jianhua, Cai Lianhong, Wu Zhiyong, |
Wise Assistant and Voice Gateway Based on Chinese TTS system SinoSonic
|
|
|
Dep. of computer Science |
||
|
Botond Pakucs |
|
|
|
CTT, Centre for Speech Technology |
||
|
Robert Batusek, Pavel Cenek, Pavel Gaura, |
AudiC – a dialogue-based programming environment
|
|
|
Laboratory of Speech and Dialogue |
||
|
Farida Orabi [withdrawn] |
|
|
|
ITI "Information Technology Institute" |
||
|
Georg Niklfeld1, Robert Finan2, Michael Pucher1 |
Voice/Visual Interfaces for Mobile Data Services
|
|
|
1Forschungszentrum Telekommunikation Wien
(ftw.), Donau City Straße 1, 1220 Wien, Austria |
||
|
Tomás Nouza |
LOTOS - system for graphic design of voice dialogue applications
|
|
|
Department of Electronics and Signal Processing |
||
|
Luca Nardelli, Marco Orlandi |
A First Step Towards Multimodal Web
|
|
|
ITC-irst, Via Sommarive, 38050 Povo Trento, Italy. |
||
|
Hervé Glotin [withdrawn] |
Pro-Active Robust
|
|
|
Dalle Molle Institute of Perceptual Artificial
Intelligence |
||
Gestual Language Introduction
João Valente and Arminda Guerra
Escola Superior de Tecnologia
Instituto Politécnico de Castelo Branco
Av. Do Empresário - 6000 Castelo Branco,
Tel: +351 272 339 335, Fax: +351 272 339 399,
E-mail:valente@est.ipcb.pt, aglopes@est.ipcb.pt Portugal
Keywords: Gestures, multimedia, learning, stories.
In the last two decades, the diseases diagnostic brightness of the cognitive forum has considerable increased, due the accessibility of available tools, which ones involve already the use of new technologies and software, and also the use of criterion that fulfills the psychometrics requirements. However, in terms of auxiliary therapy ways the resources are scarces and generally complexes for the users.
The goal of this project is a tool development that gives, in an extremely simple and bright way, the capacity to make easy the users learning, with auditory handicap.
Thus, we choose to tell an infantile story, where in each illustration, the user can select four different icons. To each icon is attributed an interactive task, where it is possible to get a better story understanding as well as the words meaning and gestures associated to the illustration. In the icons where is intended that the child give an answer (multiple choice), a positive stimulus will be given to her, in case of correct answer. In case of bad answer it will be suggested another try. It can be individually visualized the corresponding gestures to each word, and the selection of certain words in the story will allow an image or a word’s small illustrative cartoon.
In this way, we intend with telling infantile stories, go in child imaginary making her to wake up to the gesture meaning and understand it as communication way between people.
We used the stories as motivation and sensitization factor for learning, although it can be added new methodologies such as: playing with mathematics and natural sciences.
We intend to, with this tool to contribute for the fulfillment of some existents gaps, in didactic terms, concerning the existent software in the market to help children with cognitive handicap as well as their teachers and parents.
Wise Assistant and Voice Gateway Based on
Chinese TTS system SinoSonic
Tao Jianhua, Cai Lianhong, Wu Zhiyong, Wang Zhiming
tao@media.cs.tsinghua.edu.cnDep. of computer Science, Tsinghua University, Beijing, China, 100084
With the rapid progress in personal computer and network, TTS & ASR system are used more and more widely. Here, we developed Wise Assistant and Voice Gateway based on Chinese ASR system and TTS system SinoSonic, which was developed by Dep. of Computer Science of Tsinghua University and was considered as one of the best Chinese TTS system in China. The system was trained by well-designed speech database with neural network technology, and was integrated with the characters of natural and kind language and is acceptable for users. The kernel of system contains a couple of sub-modules subjected to different process of system operation, i.e., neural network training module, bi-gram based text analysis module, speech element selection module, speech synthesis module and internal communication protocol.
1. Wise Assistant
Wise Assistant is a kind of facility for PC controlling and information retrieval. It accepts oral command from the user, makes prompt action, such as answering the question with speech, exploring a website, executing a program, closing the windows, and then read all of the information for the user, etc. Further more, Wise Assistant also offers some other interesting functions. The system contains four major modules: Keyword Recognition (based on speech recognition system), Screen Reader (based on TTS system SinoSonic), Dialogue system and other functions for prompt actions.
Keyword Recognition is used to accept the oral commands from users and makes prompt action. With Dialogue system, PC can generate some answers according to the users’ question.
Screen reader is a kind of PC software used in Windows 9x/2000 Operating System. The major function of the system is to speak the results generated by Dialogue system or information retrieved by oral command. But it is not limited in this field, actually, it can read whatever appears on the screen of computer, such as the content in Word, IExplorer, Netscape, Acrobat Reader, Notepad, Outlook, etc. It behaves in three types,
1.1 It behaves as a Floating Toolbar, and read the text marked by mouse on the screen, which is shown in Figure 1. At the same time, a talking head technology was integrated into the software. A young girl will speak while her mouse moves synchronized with the speech synthesis results. With talking head technology, only one picture of person is necessary. Thus, it can be easily changed to other cartoon pictures or real person’s pictures.
Fig 1, The appearance of Screen Reader
1.2 It behaves as plugin program and inserts a new toolbar with ttsPlay, ttsStop, ttsPause functions into some typical document editor, such as Word, Acrobat Reader and IExplorer etc. Thus, it extends the power of other software with TTS function.
1.3 It reads the text spontaneously corresponding to the position of the mouse on the screen of computer.
1.4 Voice Command: to make computer act according the command through voice.
Wise Assistant not only gives a new vivid environment for PC operators and change the traditional interactive method between human and computer, but also is very useful and helpful for some people who are suffered with their eye disease.
2. Voice Gateway
Voice Gateway is a kind of middle system for speech processing. The system accepts information from others, generates the speech with TTS engine, and then transfers the results to other corresponding systems. It is shown in Figure 2.
![]()
![]()
![]()
![]()
Fig 2, The Frame of VoiceGateway
There are some special characters in Voice Gateway,
² The system can connect to other Gateways, such as Email Gateway, acting as middle module.
The system supports internal queue management and multi-module transfer.
The system can operate on more than one mainframe in terms of central control, and supports load balancing technology.
Voice Gateway is packed as an open module, supporting multiple platforms and supplying its communication function based on TCP/IP protocol. It can operate in complex network environment.
Further more, Voice Gateway can operate on any mainframe. Single mainframe supports 32 queries simultaneously. More than one Voice Gateway can be loaded at will in one mainframe in terms of load balancing control provided by this system. The central dispatcher can allocate data processing to the fittest Voice Gateway according to the working load of every Voice Gateway. Theoretically this mode can support infinite system expansion and spread Voice Gateway to any place wherever there is Internet.
Till now, Voice Gateway based on SinoSonic has been integrated into IVR, UMS etc, and been used very widely in China.
AudiC – a dialogue-based programming environment
Robert Batusek, Pavel Cenek, Pavel Gaura, Pavel Nygryn
{xbatusek,xcenek,gazi,nygryn}@fi.muni.cz
AudiC is a dialogue application serving as an integrated development environment for the C programming language. Based on the VoiceXML technology, it effectively combines some well-known techniques (multimodal input and output, user modeling) with some new ideas (grammar-based dialogue generation, navigation in the tree structure, optimizations for blind and partially sighted people). Although AudiC is developed above all as a tool for blind programmers, it can serve for learning the C language as well as the demonstration of the capabilities of nowadays dialogue systems. Let us now discuss its features in a more detail.
1. VoiceXML
VoiceXML is a markup language designed for speech-based telephony applications. We have implemented a proprietary interpreter of the VoiceXML language. Most of the system functionality is ensured by executing some prepared VoiceXML dialogues. Some more sophisticated functions of the system are implemented as special commands (so-called objects in VoiceXML terminology) defined in the dialogue description.
2. Input and output
Speech is the main communication medium of the system. Whenever it is effective, it is combined with some other types of input and output. The system accepts both keyboard commands and spoken commands as its input. As the typical dialogue of the system is the menu-like dialogue (the user selects from a limited number of possibilities provided by the system), AudiC can be controlled, for instance, from the cellular phone. The output of the system is usually the synthesized speech. However, a combination of synthesized speech, prerecorded speech, earcons and background sounds is often used to speed up the information flow.
3. Automatic dialogue generation
This new idea enables us to derive a significant part of the dialogue system automatically. We have designed a tool converting the grammar of the C programming language to a set of dialogues written in VoiceXML. These dialogues present the system messages, collect responses from the user as well as generate the source code. The conversion tool takes the grammar of the C language as a parameter and can be easily adapted to another programming language.
4. User modeling
Programming is usually a long-term task and each user has different habits. Thus, customization and configuration are very important features of each programming environment. AudiC supports customization at many levels – system output (user-specific earcons, types of speech), source code (both textual and spoken remarks), dialogue (so-called shortcuts in the dialogues generating source code). Moreover, AudiC builds the user model automatically by monitoring the user activity.
5. Navigation in the tree structure
Each program source code is a tree-structured document. Common integrated development environments try to illustrate this structure by the text indent. Thanks to the process of the source code generation based on the C grammar (see item 3), a tree (similar to a syntactical tree) is the natural structure of the source code in AudiC. The system is equipped with commands for navigation and orientation in the tree structure as well as with commands for the tree structure editing.
AudiC is a tool offering a different approach to programming. We believe that the features of the system allow fast and comfortable code generation and editing.
Eloquence
Farida Orabi
ITI "Information Technology Institute", Egypt
fa_orabi@hotmail.com
Eloquence is a website designed to give satisfactory information about all aspects of speech production. It acts as an encyclopedia (providing complete information about mechanisms of speech production, defective patterns of speech and language, IPA as well as an anatomical view), it includes also user-interactional applications (in that it diagnosis the disorders, assess them and then suggests the suitable therapy as well as an automated articulation test).
It is devided into several topics dealing with nearly all specializations concerning speech production science
Mechanism of speech production
Speech and language disorders
Available therapy to the mentioned disorders
Diagnosis
Articulation test
However, this website is not for peers only but also for non-professianals, thus a dictionary of all scientific terms is provided to prevent any ambiguity in the information introduced.
Voice/Visual Interfaces for Mobile Data Services
Georg Niklfeld1, Robert Finan2, Michael Pucher1
1Forschungszentrum Telekommunikation Wien (ftw.),
Donau City Straße 1, 1220 Wien, Austria
1Mobilkom Austria AG, Obere Donaustraße 29, 1020 Wien, Austria
Email: niklfeld@ftw.at, r.finan@mobilkom.at,
pucher@ftw.at
We believe that commercial breakthrough for speech technology in the next years will come not through technical revolution, but through deploying mature technologies in mass-market application scenarios where they work best. While we do not predict the killer-application for 3G mobile networks, we imagine that 3G mobile networks will be the killer-application for speech technology.
Good visual human-computer interfaces are effective, and often not less "natural" than voice interfaces. But visual interfaces to mobile data services on 3G devices have some real problems:
Many 3G devices will not have a keyboard for text entry.
Displays will always be too small to fit all desirable information and controls.
Users will want to use some services also when their eyes, hands or both are distracted.
In this situation, adaptive multimodal voice/visual interfaces that combine the strengths of voice and text/graphics interfaces can yield significant benefits for usability.
Therefore we looked for a development model that should empower every third-party developer of mobile data services to add speech control to their service; not to replace a visual interface, but as an additional option or support for it. For mass-market potential, a suitable development model must be as simple and open as possible. Web technologies fit well, and they are already used in visual interface development. VoiceXML [1] is the voice technology that delivers the required characteristics. Unfortunately, both the current web technology for mobile devices and VoiceXML are designed in a way that does not provide easy extensibility to multimodal interfaces. The problem is known, a working group is being set up at W3C, but no bridging standard will be available in the near future.
Our submission is a generic architecture for voice/visual interfaces (cf. [2]), using VoiceXML that we have designed and subsequently implemented in a demonstrator that we will exhibit. The demonstrator adds speech input capabilities to an existing route-finder web-application for the city of Vienna. It makes use of application features (city-district information restricts possible street names) to achieve low ASR error rates and to demonstrate a usability advantage of the voice-enhanced interface for address entry without a keyboard. Though in need of further refinement, the architecture can serve as a guideline for development of voice/visual interfaces to mobile data services, and it can do so in the short-term perspective that is necessary to get a broad base of voice/visual enabled mobile data services ready by the time of a successful mass-market launch of UMTS.
Of the different types of multimodality distinguished in [3], the demonstrator provides type 1 multimodality (sequential), while our architecture also supports type 2 (uncoordinated simultaneous). We are currently trying to identify mobile data services that would call for "full" multimodality type 3 (coordinated simultaneous events on different modalities). Particularly on this issue we are looking forward to ideas and feedback from visitors of the Imagination 2001 event.
References
[1] W3C (2000), Voice eXtensible Markup Language (VoiceXML)
version 1.0, http://www.w3.org/TR/2000/NOTE-voicexml-20000505/
[2] G. Niklfeld, R. Finan, M. Pucher (2001), Architecture for adaptive
multimodal dialog systems based on VoiceXML, Eurospeech 2001.
[3] W3C (2000), Multimodal requirements for voice markup languages.
Working draft 10 July 2000, http://www.w3.org/TR/multimodal-reqs
LOTOS - system for graphic
design of voice dialogue applications
Tomas Nouza
Technical University of Liberec, Halkova 6, 461 17 Liberec, Czech Republic
jan.nouza@vslib.czForm of presentation: The described system can be demonstrated using a PC (own notebook) and data-projector. The TTS and ASR modules, however, will communicate with the user in Czech only.
Since my 15 I have been working as external collaborator of SpeechLab at Technical University of Liberec (TUL). Recently I have been responsible for running, maintaining and upgrading the system InfoCity, which is a public (non-commercial) telephone operated information service employing voice technology developed at TUL [1].
My own experience with the above system made me develop a new platform that should allow for more efficient and user-friendly design of similar applications. A typical service of this type uses a computer-driven approach with more or less predictable scenario. Decomposing such a scenario we get a small number of elementary actions, namely TTS output (system prompts, announcements and questions), speech input followed by key-word recognition, dialogue branching depending either on input data or on the system state, database query with constraints specified by the user, etc. Each of these elementary actions can be viewed as an object with its own properties, methods, events, input and output points. Moreover, the objects can be represented by graphic symbols that can be easily organised on computer screen in order to design a meaningful scenario. The idea is not new, it has been previously applied in the RAD system developed by OGI [2]. The RAD seems very well-suited for demonstration and tuition purposes, however, some of its features make its use in real-world applications ineffective. The RAD objects occupy too large space on the screen mainly because of the need for interconnecting lines. According to my knowledge the RAD has only a limited support of dialogue variables, it does not allow their use in complex expressions and it seems to have no interface to databases.
The system I have developed and named LOTOS tries to go beyond the above mentioned limitations. The LOTOS objects, here called bricks, have been created and formed to cover most situations occurring in the design of typical voice transaction service. Its scenario can be built from bricks representing 8 types of actions: a TTS output, an ASR input, a combination of TTS question followed by recognition of the user answer, a dialogue switch, a jump in scenario, expression evaluation, time synchronisation and a database query. Each brick has a number of properties that may be set up individually to fit the given application. The ASR brick can store the recognised input into variables and the variables can be interpreted and read by the TTS brick. In most cases the variables serve for specifying the query when the database is to be accessed. However, they may be used also for counting, calendar and time evaluation, or e.g. for driving the dialogue scenario by data from the external database. The bricks have been designed in the way so that they occupy minimum space on the screen. No interconnection lines are needed since the bricks lie each on other and multiple output points are added on demand. To make the scheme compact and linear, only the path going to the currently active brick is displayed in complete. All the other paths are hidden temporarily being just indicated by diminished shapes. This feature allows the designer to place even large plans on relatively small and compact space of the drawing sheet. For details - see our Eurospeech2001 paper [3].
Being an easy tool for user, the LOTOS is in fact a quite large and complex program, particularly due to its sophisticated graphic features, the need for on-line evaluation of complex expressions and for its capability to run in three modes: the design mode, the debug mode and the run mode. It has been written in Visual Basic with support of DLL modules made in C++.
References
Nouza J., Holada M.: A Voice-Operated
Multi-Domain Telephone Information System. Proc. of ICASSP’2000, Istanbul,
June 2000, vol.VI, pp.3755-3758
Sutton S., Novick D., Cole R., Vermeulen P., Villiers J.,
Schalkwyk J., Fant M.: Building 10,000 Spoken Dialogue Systems. Proc. of ICSLP’96,
Philadelphia. October 1996, pp. 709-712.
Nouza T., Nouza J.: Graphic platform for designing and
developing practical voice interaction systems. Proc. of Eurospeech2001.
Aalborg, September 2001.
A First Step Towards Multimodal Web
Luca Nardelli, Marco Orlandi
ITC-irst, Via Sommarive,
38050 Povo Trento, Italy.
(lunarde@itc.it, orlandi@itc.it)
At present, it is very widespread for people to access the Web with Internet connections using HTML and/or WML browsers. There are different ways for interacting with Web sites; W3C is proposing methods and system architectures to allow Web access via voice
browsers, using ASR, TTS and telephone capabilities. In this way any user will be able to access Web-based services by telephone, and this will be an advantage expecially for people with handicap. Furthermore, this technology will be necessary for handling hands and/or eyes free interactions and will become fundamental in the next generation cellular system, where mobile terminals will have, in general, reduced input/output capabilities. In this last case, the development of "multimodal" browsers, i.e. voice input/output plus input/output from other devices (e.g. graphic pointing, touch screens, small numeric keyboards, etc...), should satisfy the user requirements.
The idea we propose consists in the definition (and consequent realisation) of an architecture capable of handling multimodal browsing through the synchronization of HTML and VoiceXML documents. In doing this, we have to consider issues related to the variability of user/terminal profiles, as well as issues related to the layout adaptation to different presentation modalities (e.g. spatial/temporal axes and hyperlinking). VoiceXML enables users to browse documents by speaking and hearing on a phone, but does not support a graphic interface as HTML and WML. We prefer to synchronize different documents through a specific platform instead of adding new features to existing HTML, WML or VoiceXML documents. This is substantially different from the multimodal requirements proposed by W3C (see http://www.w3.org/TR/2000/WD-multimodal-reqs-20000710), where "multimodality" is inserted within the multimodal MarkUp Language specification. However our approach has the advantage of allowing, in a quite general way, multimodal browsing of existing HTML documents by developing corresponding VoiceXML documents.
In Figure 1 the overall architecture of the system is shown. The clients of the Web server can be a standard Internet "graphic browser" (e.g. NetscapeÒ) or a telephone platform. The Web server contains HTML/WML documents and associated VoiceXML documents. A
speech server provides both ASR and TTS functionalities. The multimodal browser fetches documents (these can be HTML/WML documents or VoiceXML documents) from the Web server, interprets them, and handle the communication with the graphic browser or with the
telephone platform. The multimodal browser also communicates commands and receives results from the ASR/TTS on the speech server side. Note that the speech signal can be acquired through a microphone on the client PC or through telephone boards on the telephone platform. The speech signal can be directly sent to the speech server or can be sent, via IP, to the multimodal browser as well (and from this last one to the speech server).
Figure 1
If the client is a standard Internet graphic browser the HTML/WML documents can be synchronized with the VoiceXML ones through an Applet Form and JavaScript (see Figure). When the user changes the HTML/WML document, e.g. by typing or by pressing the mouse, the JavaScript code is ready to notify the Applet Form of this. Then, this last one updates the VoiceXML interpreter context about HTML/WML document changes. When the user changes the VoiceXML documents by speaking into the microphone (note that also in this case an Applet
sampler sends the signal to the speech server), the VoiceXML interpreter context notifies the HTML/WML interpreter of VoiceXML document changes. Finally, an Applet TTS could receive and play synthetized speech. In practice, the interpretation of documents is demanded to the multimodal browser, while the graphic browser and/or the telephone platform are asked only to provide input/output.
If the client is a telephone platform we have only VoiceXML document navigation. In this case user may speak and press buttons to enter a single request.
This approach makes easy to combine different input/output modalities - in this way form filling can be easily realised by both typing or speaking. However, there are some problems on Markup Language syntax to point out. For example, it is not always possible to automatically generate a visual component (HTML/WML documents) from the verbal component (VoiceXML documents, voice prompts, grammars, ...) and viceversa.
Finally, we worth note that quite all the components of the system (ASR, VoiceXML interpreter, etc...) has been developed in our Labs, some of them (e.g. the VoiceXML interpreter) by us.
Pro-Active Robust
Automatic Speech Recognition
Hervé Glotin
ICP, Grenoble, France
& IDIAP, Martigny, Switzerland - glotin@icp.inpg.fr
The aim of this project is to reinforce robustness of a multi-stream speech reco-gnizer, using a feed back loop issued from the output phonemes' hypothesis and affecting expert fusion and features extraction stages. The key idea is to use phonemes recognition to anticipate and prepare recognition, this follow Gibson, who points out that information cannot be said to cause perception : « Perception is not a response to a stimulus but an act of information pickup…Such a system is never fully stimulated but instead can go into activity in the presence of stimulus information » [1].
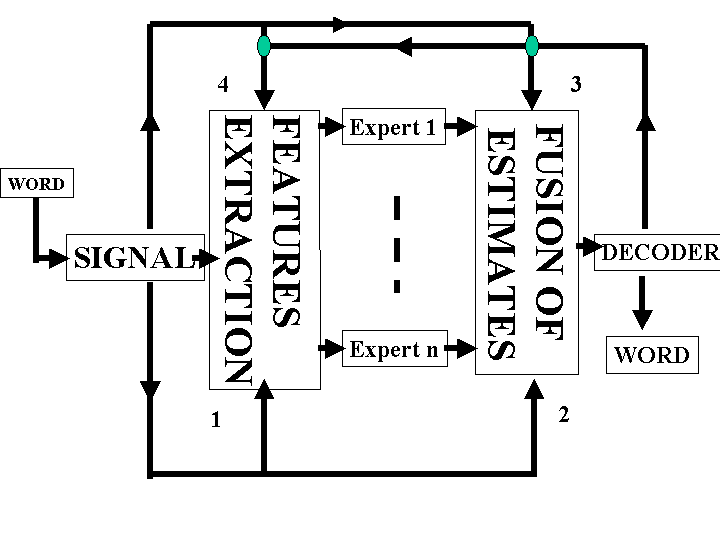
This figure presents the architecture of the Pro-Active ASR (PASR). Like in previous works, various features (audio or/and visual) are extracted from signal. Each stream feeds expert recognizer. Their estimates are combined through the fusion process, and feeds a decoder. It has been shown [2,3] that a signal reliability cue, like voicing, reinforces feature extraction using a Wiener filter through path 1. The same information can reinforce expert fusion through path 2 [2,4]. The feedback loop is starting from the decoder, providing phonetic context to the fusion stage (path 3), or to the features extraction (path 4). Neurophysio-logical parallels can be found for both path. Path 3 is demonstrated in [5]. It consists on a bias prediction of the phonetic estimates which depends on the signal reliability. It can be improved and extended to Path 4. Typically, some features are optimal for the robust transmition of some particular phonemes.So if some phonemes are assumed to be present, it is releavant to "focus" on these features. It is the key of the PASR : it integrates signal reliability and best phonetic hypothesis, emphasizing, for few iterations, the most appropriate features according to the most likely phoneme. This is linked to the Maximum Discrimination Information principle where a state-dependant feature transformation incorporated into the structure of the HMM improve recognition [7].
Path 4 can also be used to synthetise speech [6] and then re-estimate SNR.
We assume that the likelihood will increase only for correct hypothesis based on its progressive reinforcement.
We expect that PASR will reinforce the robustness of the recognizer leading to the restoration effect.
[1] Gibson, The ecological approach to visual perception. Hillsdale, 1986
[2] Glotin, Phd Thesis, Elaboration of robust multistream automatic speech recognition using voicing and localisation cues, INP Grenoble, June 2001.
[3] Berthommier, Glotin and Tessier, A front-end using the harmonicity cue for speech enhancement in loud noise, ICSLP 2000.
[4] Glotin, Vergyri, Neti, Potamanios and Luettin, Weighting schemes for audio-visual fusion in speech recognition, in ICASSP 2001.
[5]Glotin, Optimal fusion of expert’s confidence and speech reliability for robust multistram ASR : the PBP model, in IEEE int. Wksp on Intelligent Signal Porcessing, 2001.
[6] Pratibha and Hermansky, Temporal patterns of critical-band spectrum for text-to-speech, in ICLP 2000.
[7] Rathinavelu and Deng, HMM based speech recognition using state dependent, discriminatively derived transformation on mel-warped dft features, IEEE TSAP 5(3), 1997.